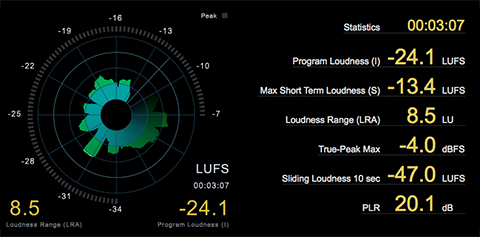
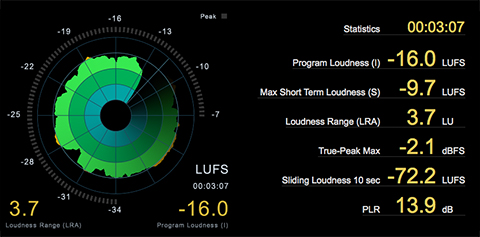
Scenario:
Studio Host and Skype participant to be recorded inside Logic Pro X on a single machine (single pass) with no additional hardware other than a Mic Input Device.
Objectives:
[– Two independent mono Host/Participant stems with no processing.
[– One processed split-stereo mixdown of the session with the Host and Guest residing on discrete (L+R) channels.
[– Real time Processing and Recording of all instances.

Of course the objectives noted above are easily attainable using two independent machines, with the recording box running Logic Pro X and the Skype machine handling the connection. In this case you would also need to use a mixer to set up a proper mix-minus.
You can also implement similar workflows by using two inexpensive USB audio interfaces connected to a single machine.
Considering the resourcefulness of today’s modern day Macs, I’m confident the following workflow will be successful freeing the user from complexities and added costs.
OSX Aggregate Devices
The foundation of this setup is based on a user created Aggregate Audio Device. Aggregate devices appear in the OSX System Preferences/Sound I/O options for system wide use. By wrapping supported “Subdevices” into a single Aggregate, you effectivly create a sort of cumulative Input Device that can be designated in Logic as the default. We also need a software utility that supports routing of the Skype Output to an Input in Logic.
I originally created this workflow using SoundFlower that was installed on my secondary iMac and carried over form previous versions of OSX. SoundFlower, along with the iMac’s Line Input were wrapped into a single Aggregate Device, and then designated in Logic as the default Input.
This worked well. However, I had no plans to install the now unsupported SoundFlower on my production MacPro for further testing. And so I looked around for a suitable up to date (and actively developed) replacement for SoundFlower.
Sound Siphon
Sound Siphon by Static Z Software “… makes your Mac’s Audio Output available as an Audio Input Device. It enables you to send audio from one application to another where it can be processed, streamed, or recorded.”
Exactly what I needed.
Note that Sound Siphon is very diverse in terms of features. And the developer states that many useful enhancements are in the works. You can download a restricted demo. My hope is that you consider purchasing a $29.99 license. This will ensure the longevity of the application and continued development. Note that I have no affilation and I gladly purchased a license.
This is a snapshot of Sound Siphon:

In the example above I display a user defined Device (“Capture Safari”) that is essentially a Custom Audio Input. I then associated the Safari Application with this device. This becomes a system wide option to capture Safari audio. For example QuickTime X will now display “Capture Safari” as an Input option for audio recording.
It’s important to note that this particular Sound Siphon feature is supplemental to the Skype recording implementation. In other words – it’s an entrley different use case scenario. My goal here is to disclose the flexibility of the application.
Creating the Aggregate Device
Input 1 on my Mackie Onyx 1220i Mixer receives the output from a dbx 286A Voice Processor. The studio Mic is connected to the processor for proper gain staging. I needed to wrap the Mic signal along with the Skype audio into a single Input Device and designate it in Logic’s Preferences for proper routing.
To create an Aggregate Device, open Audio MIDI Setup, located in ~/Applications/Utilities. When creating a new Aggregate, supported Subdevices appear in the right side setup table.
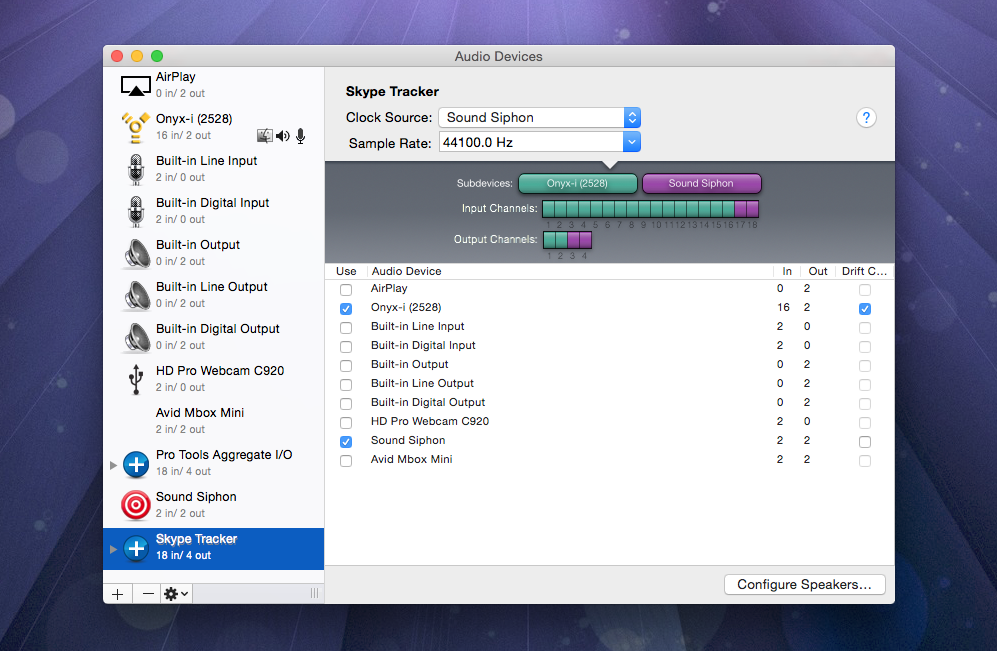
Notice that Sound Siphon is listed as a 2 in/2 out device in the left source view. This is created when you install the application. Once installed, it will be available to be wrapped into an Aggregate Device along with pre-existing devices.
For my implementation I created “Skype Tracker” as a new Aggregate and selected my mixer (Onyx-(2528)) and Sound Siphon as Subdevices. Up top you set your Sample Rate and the Clock Source. My system seems to perform better with Sound Siphon set as the Clock Source.
It’s important to review the Input Channel matrix of the new Aggregate Device. Notice that Sound Siphon will only support Input channels (17+18). When routing Inputs in Logic, I will use Input 1 for the studio Mic and Input 17 for Skype.
Skype
Here are the Skype settings that I am using:
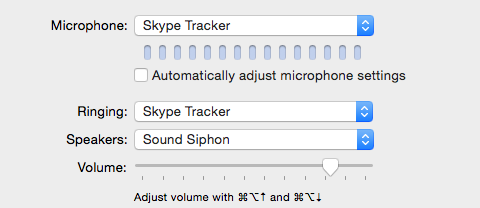
The Microphone is set to the Aggregate Device. The Speakers option is set to Sound Siphon. This setting is imperative and from what I can tell non-flexiable.
Logic Pro X
The first thing we need to do is define the Input Device in Global Preferences/Audio/Devices. I set mine to the Aggregate Device:
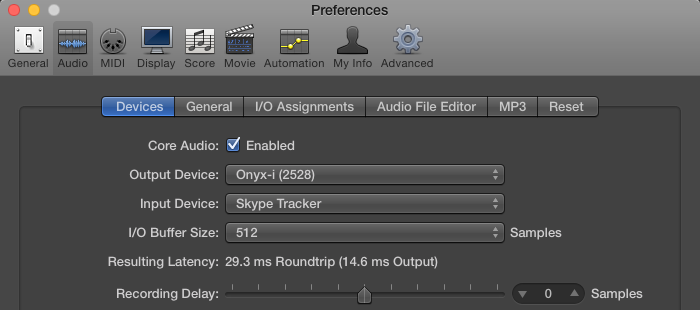
Next we will address setup and routing. What’s important here is that I use an Object in Logic that may not be immediately obvious in your particular installation.
Specifically, I often use Input Channel Strip Objects in my projects. They are implemented in the Environemnt (aka “MIDI Environment”). It is accessible form the Logic Window Menu.
From the Logic Docs regarding Input Channel Strips:
“The Input Channel Strip allows you to directly route and control signals from your audio hardware’s Inputs. Once an Input Channel Strip is assigned to an Audio Channel Strip, it can be monitored and recorded directly into Logic Pro, along with its effect plug-ins.
The signal is processed, inclusive of plug-ins even while Logic Pro is not playing. In other words, Input Channel Strips can behave just like external hardware processors. Aux sends can be used pre- or post-fader.
Input Channel Strips can be used as live Inputs that can stream audio signals from external sources (such as MIDI synthesizers and sound modules) into a stereo mix (by bouncing an Output Channel Strip).”
You can also create Bus Channel Strip Objects in the Environment. They are not the same as Auxiliary Channel Strips and can be quite useful in certain instances. For more information about Bus Channel Strips please refer to this article.
The Environment
To expose the accessibility of the Logic Environment, open global Preferences and access the Advanced options. The MIDI option needs to be selected as part of the Advanced Tools:

Once that setting is ticked, “Open Midi Environment” will appear as an option in the Logic Window Menu.
Channel Strip Objects are added to the Environment from the New Menu/Channel Strip. Notice how the Environment emulates the Project Mixer:

Note that when adding Input Channel Strips in the Environment, you must define the corresponding (Aggregate) Device Inputs using the Channel Strip editor:

For this particular project I created two Input Channel Strips in the Environment using Inputs 1 and 17 respectively, based on Aggregate Subdevice availability (Input 1 = Mic, Input 17 = Skype).
You will also need 4 Audio Tracks (2 Mono, 1 Stereo, 1 PreListen), and 2 (Mono) Auxiliary Channel Strips. Create Audio Tracks using the Track/New Tracks option – located in the Logic Application Menu. Add Auxiliary Channel Strips using the Mixer’s Options Menu/Create New … || Note that the Input Channel Strips created in the Environment should be designated Mono.
Here is my Project Mixer with all necessary Objects and Routing:

Routing
The reddish labeled channels are the two Input Channel Strips that I created in the Environment. If you look at the text at the very top of these Channel Strips, you will see their Input designations.
The signals coming in through the Inputs are routed to their own independent Aux Channels for processing. Notice I inserted a Gain Trim on the Mic Input Channel. All processing options are of course subjective. One example would be to insert two instances of a Compressor on each Aux Channel. You would set these up to apply real time, non-aggresive dynamic range compression as you record.
Moving forward – notice the Aux Channels are Mono and hard panned L+R respectivly. This will maintain channel separation when recording the split-stereo version of the session. In this example each Aux Channel Output is routed to Audio Channel 3 (“Split Record”). This Stereo Audio Track is panned center. When armed it will record the Aux Channel Outputs to a split-stereo file.
Also study how I set up the remaining Audio Tracks – Audio Track 1 (“Rec. Mic”) and Audio Track 2 (“Rec. Skype”). Their Inputs are set to Bus 1 and 2 respectively, allowing these tracks to receive the unprocessed Outputs (“dry” audio) from the Input Channel Strips.
Keep in mind that if Effects are inserted on the Input Channel Strips, the audio routed to Audio Tracks 1+2 will be processed. In most cases I would not insert any Effects on the Input Channel Strips other than Gain. My intension here is to record dry stems.
I Grouped various aspects of these two channels, mainly Volume, Mute, Solo, and Record. This will link the faders and make it easy to control audibility of the mono stems cumulatively.
Wrap Up
That’s basicilly it. You can record/monitor all tracks in real time. And when you are done, there is no need to bounce, although you still can. You simply “Export” or “Export Region” as an individual file(s).

Notes
You may have noticed the Outputs for the Auxiliary Channel Strips (1+2) and the Input for Audio Track 3 (“Split Record”) is Bus 3. This is in fact a virtual (permanent) Bus used to route the processed audio to Track 3 for recording.
When you select a permanent virtual Bus in Logic for routing, an Auxiliary Channel Strip is auto-created and will appear in the Mixer. For this particular workflow – we use two Auxiliary Channel Strips, one for Mic processing and a second for Skype processing.
Throughout this entire workflow no changes were made to my default OSX Audio I/O Settings located in System Preferences/Sound.
As I always say – Audio Tracking and Post are highly subjective arts. In fact many Logic “experts” have never heard of or utilized the options in the Environment. And your processing options are also subjective. My hope is this documentation will at the very least introduce you the creation and usage of Aggregate Devices.
If by chance you develop a successful alternative solution, all well and good. In my tests I’ve found the documented implementation to work quite well.
Let me know if you have any questions.
I’d like to thank my friend Victor Cajiao for his help while testing this workflow.
-paul.









.jpg)
.jpg)
.jpg)
.jpg)